Unités de Traitement
1. Formalisme.
2. Description des unités de traitement.
3. Découpage d'une U.F en U.T.
1. Formalisme.
Les premiers modèles de représentation interne des traitements
se limitaient aux travaux par lots, c'est à dire en temps différé,
ou en batch. Ces modèles ont du être adaptés avec le
développement des travaux en temps réel, modes conversationnel
ou interactifs. Les méthodes modernes ont apporté d'autres
modèles pour ce deuxième type de traitement : ce sont les
unités de traitement.
Une U.T. est représentée par un organigramme de
données (comme une U.F.), dont le dessin utilise un formalisme organique,
c'est à dire précisant les supports : bandes magnétiques,
disques, etc.
Une U.T. correspond à un programme, à un passage d'instructions
en mémoire centrale, ou à un ensemble de modules de programmes.
U.T. de paie
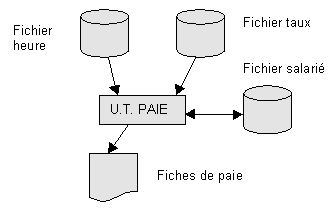
Le formalisme des U.T. est bien adapté aux fonctions à
réaliser en temps différé. Pour les autres fonctions,
il ets préférable d'utiliser d'utiliser des diagrammes homme/machine,
des descriptifs détaillés de traitements, ...
Symbolisme des U.T.
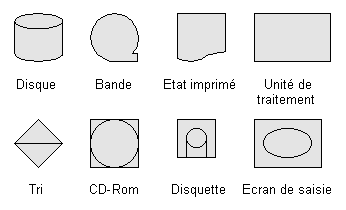
2. Description des unités de
traitement.
Pour chaque U.T. il est nécessaire de décrire :
Ex : reprenons l'U.T. paie précédente
et complétons la.
FICHE DESCRIPTIVE DE L'U.T. PAIE
But : édition des fiches de paie.
Périodicité : 28 du mois.
Organigramme des données :
Fichiers permanents :
Nom de fichier, mode d'ouverture (INPUT, OUTPUT,
I-O), organisation (SEQUENTIAL, RANDOM, RELATIVE, INDEXED), accès
dans le programme (SEQUENTIAL, DYNAMIC, RANDOM), clé (nom du champ).
Documents de saisie.
Etats imprimés.
Images d'écrans, Enchainement des écrans.
Règles de programmation :
Les descriptifs des fichiers (DATA DIVISION
en Cobol, tables DB2 ou Oracle, ...) doivent être suffisament détaillés
pour que le programmeur puisse travailler sans avoir à réinterviewer
l'analyste ou l'utilisateur. Ils doivent pouvoir permettre d'écrire
les programmes eux-mêmes (procédure DIVISION en Cobol, instructions
SQL, ...). On les présente sous deux formes :
 Sous forme d'un texte recueilli lors de l'interview, par exemple : "les
personnes dont l'ancienneté est inférieure à un an
n'ont pas droit à une prime, ceux dont l'ancienneté est supérieure
ou égale à un an, qui sont mariés...".
Sous forme d'un texte recueilli lors de l'interview, par exemple : "les
personnes dont l'ancienneté est inférieure à un an
n'ont pas droit à une prime, ceux dont l'ancienneté est supérieure
ou égale à un an, qui sont mariés...".
sous forme d'un algorithme (Si... Sinon...), d'un arbre programmatique ou d'une
autre représentation structurée.
3. Découpage d'une U.F. en
U.T.
Le découpage d'une U.F. en U.T. comporte deux parties :
Le découpage de la fonction, ou de l'unité fonctionnelle, en
programmes appelés unités de traitement (U.T.).
La description de ces U.T. (cf la fiche d'U.T. présentée ci-dessus).
Le découpage en unités de traitement provient de la recherche
d'un arbitrage entre deux critères conccurents.
Utiliser au mieux les matériels dans chaque unité de traitement, et
donc essayer de regrouper au maximum les opérations
dans la limite des périphériques et de la mémoire
disponibles.
Simplifier et répartir le travail de programation, les tests, la maintenance,
en tenant compte des logiciels, et progiciels existants, ainsi que des
fichiers intermédiaires dus aux interfaces.

